
KEG vs RAG - Why Knowledge-Engineered Generation is the Future
TL;DR: RAG is only as good as the text in the store it retrieves from, and what's retrieved is only useful as context. KEG, on the other hand, uses engineered knowledge to provide exactly what's needed.
Why Do We Need Either?
AI Language models are trained on a subset of public domain knowledge. This means that most of the people, problems, products, services, facts and opinions that matter to you aren't a part of the model's thinking.
Either because you keep these private or because they're not deemed important enough to include.
If we want a language model to use these facts, we have three options:
- We can train a new model to include them. This is expensive and requires volumes of quality training data - so it's usually beyond most organisations.
- We can "fine-tune" an existing model. This is less expensive and requires less training data but it may not give us the results we need. Why? Because fine-tuning generally-capable models (like the GPTs for example) makes them less useful when they're applied to tasks outside the fine-tuning data set. In extreme cases fine-tuning can even result in "catastrophic forgetting". Many tasks need that "general" knowledge.
- Our third option is to provide the language model with the extra facts it needs as part of the context window - the sequence of tokens that are sent to the model at query time. In other words to "augment" the "prompt". We call this Context Completion - the process of providing every fact a model needs to complete a task.
Retrieval Augmented Generation (RAG)

RAG is a Context Completion strategy. A task or query is examined, text is "retrieved" from an external store and the two are fed together (perhaps with some manipulation) into a Language model.
There are three broad classes of RAG:
1. Small Document
The simplest RAG architecture is a pre-prepared document that can be used as context. This is the basis of the common "Chat With My ..." question answering (QA) pattern. Chat With My PDF, Chat With My Website, Chat With My Pasted Block of Text...
2. Big Document
A big document (or a few of them) can also work as context for summarisation, synthesis and other more sophisticated use cases. It can only be used, however, with a language model that has a large context window - of which there are few.
3. Document Chunks
A more scalable solution is to store many small documents or "chunks" of text and then collect the pieces needed for context completion at query time.
A variation of this pattern is to generate the chunks at query time from a structured data source like a CRM or a product database. The store of text chunks is indexed - either traditionally, or using "embeddings" (vectors) which can be better at finding semantic similarity when the exact words stored aren't used in the query.
RAG Limitations
Each architecture has its problems. Before discussing these problems, it's worth examining some Large Language Model features and terminology:
Perplexity - is a measure of the average number of equally-likely next-word alternatives available during text generation. I.e. the degree to which a language model is "perplexed" by its choices.
Hallucination - a fact claimed by an AI that is false, an entity claimed that does not exist or a feature generated by the AI that is imagined.
Unsurprisingly, use cases that can be satisfied with a small, concise, well-written document are the most reliable. There's little risk of perplexity and if you only ask about what's written in the document, the language model won't hallucinate. Even better, you can "fine-tune" the LLM's responses just by editing that document. The problem is that a single small document is typically only useful for a trivial application.
Applications using big documents and large context windows can do more, but they introduce issues of their own. Aside from making the query slower and more expensive, the strategies used to squeeze the large context document into a model dilute the usefulness of that context. Large-context models currently tend to misunderstand or ignore some data - particularly if it's in the middle of the input. Even more problematic is the scope for perplexity in legacy documents that were written for other purposes. Using them seems like an easy win, but confusing duplication and rhetoric is common in legacy data sources.
Indexed chunks of context - documents or otherwise - tend to be even more problematic. This is not because of any underlying mechanistic flaw, but because the push to use this approach is driven by several fallacies:
The Divisibility Fallacy
A document is more than the sum of its parts. As it tells its story, the reader creates a picture and builds important contextual relationships that allow him to make sense of each new piece of information as it's introduced. If the document is divided, much of this context is lost - particularly for concise, well-written documents with little redundancy.
Books have indexes, websites have hyperlinked pages and scientific journals have references for a reason - because it almost always takes more than what's in the current attention window to fully understand its contents.
The Big Data Fallacy
If your child wants to learn about (say) neurons, do you tell her to do a "neuron" Google search and read every result? Or do you point her to the relevant section of a text book?
A human doesn't need to see the same fact written a hundred different ways to understand it. As it happens, the most capable LLMs don't either. GPT3, GPT4, Claude, Palm2... these are in-context and zero-shot learners. They need only as much context as a human does. More is not better - it actually results in perplexity and less-consistent results.
Collecting as much data as you can makes sense for analytics projects and when "training" large Language Models. It makes no sense for a knowledge store, however.
The Easy Win Fallacy
Every organisation has existing knowledge coded in legacy documents, knowledge bases, Content Management Systems, emails, websites, collaboration tools, support logs, databases and a host of other stores. RAG promises ChatGPT-like functionality that makes use of all this legacy knowledge. You just have to "ingest" the knowledge into a Vector Database and then use the database to find what's needed at query time.
These sources, however, are the product of human memory, creativity and interaction. They're full of duplication, rhetoric, conflicting views, poorly-constructed statements, jargon, obscure acronyms, out-of-date and often wrong information. Add to this the divisibility and perplexity problems already discussed and you can see that there's no easy win in using legacy knowledge sources.
If the text is garbage, it doesn't matter how good the indexing is.
Given its current hype, it's worth discussing the role the vector database plays in this "easy win" fallacy. Sure, it's a great new technology and a significant advance over keyword indexing in many cases. But it's just a semantic index over blocks of text. If the text is garbage, it doesn't matter how good the indexing is.
If you're using one you should also be mindful that the "forced choice" and "near enough is good enough" nature of vector-based retrieval mirrors the LLM mechanisms that result in hallucination. What a vector search brings back will often be wrong if what it's looking for is missing in the database but similar to what's actually stored.
RAG is a one-Trick Pony
Retrieval-Augmented Generation is a convenient strategy that usually gives better results than fine-tuning a model - particularly when using the larger models to answer questions against your own data.
If your application is going to be using a secondary store of knowledge, however, there's scope to do much more with it than just giving it to your LLM as context. At the very least, you could be withholding or censoring context if it doesn't comply with your governance needs.
There's already a discipline devoted to structuring knowledge in support of these sorts of tasks. It's called Knowledge Engineering.
The Rise and Fall(?) of Knowledge Engineering
Knowledge Engineering as a discipline has its roots in the 1970s. Its goal was to create systems that could replicate human problem-solving. Four decades of intense effort towards that goal followed.
Expert Systems in the 1980s, which used rules and facts to mimic human expertise in specific areas.
In the 1990s, Computational Ontologies providing a structured framework for organizing, integrating and reasoning about information. At the turn of the century the W3C Semantic Web aimed to make the entire internet one large ontology that was understandable and usable by machines.
More recently, the focus of Knowledge Engineering has shifted towards Knowledge Graphs - interlinked descriptions of entities – objects, events, or concepts. These graphs currently underpin the world's largest stores of structured knowledge.
Before neural networks came to prominence, Knowledge Engineering was the biggest part of AI. My 1000-page Year 2003 AI textbook has just 16 pages on neural networks.
To most, Knowledge Engineering is now just a footnote in the AI story, but discarding four decades of human intellectual effort is a mistake. Engineered knowledge can be a valuable complement to Large Language Models and other Generative AI. We just need an architecture that helps them to work together. KEG is that architecture.
Knowledge-Engineered Generation (KEG)
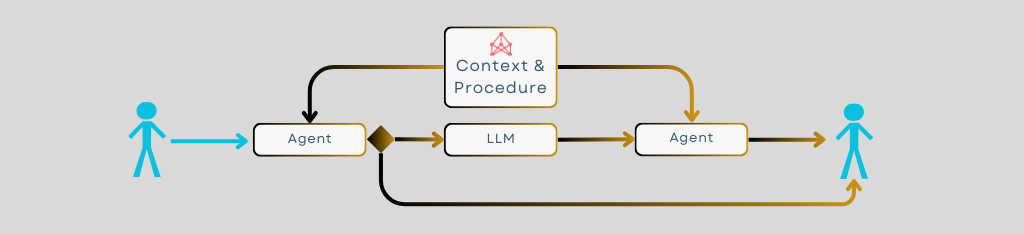
- An agent accepts a query and collects from one or more knowledge graphs the contextual and procedural concepts it needs to assess and respond to that query. It may respond directly at this stage.
- If it's to use an LLM, it will package permitted concepts as context, together with other prompt elements, and pass them to the LLM for completion.
- It will then use the concepts to assess the completion and modify it, if required, before using the completion to respond to the query.
The Heart of KEG - The Knowledge Graph
A Knowledge Graph is a digital structure that represents knowledge as concepts and the relationships between them (facts). It includes an ontology that allows both humans and machines to understand and reason about its contents.
A knowledge graph is very different from a set of arbitrarily chunked documents. In a properly-constructed knowledge graph, a concept or fact exists just once. This makes information easy to find, easy to put into a list of choices and easy to change globally at a moment's notice.
Anything you need to know about that concept is adjacent to it in the graph, so it's also easy to package up the context needed by an LLM. The semantically-connected nature of the graph also makes it possible to control application behaviour for broad classes of knowledge.
Trust, Explainability, Accuracy & Consistency
LLMs are unpredictable black boxes - it's impossible to explain exactly how an answer is generated, and output is often inconsistent. Sometimes they'll even make stuff up - a behaviour referred to as hallucination or confabulation.
Using external data for context completion can solve all of these problems. What's required, however, is that the provided knowledge exactly match the needs of the query. This is what knowledge graphs were designed for.
Human-in-the-Loop
A knowledge graph will let you browse and move around its contents. Two decades of web with its billions of links has shown this to be a highly-valued mode of information discovery. Browsing also affords more opportunity for a "human in-the-loop" to select the context that's passed to a Large Language Model. Sure, many RAG-based applications can cite their sources - but a human-controlled "get it from this" is far superior to a machine-reported "this is where it came from".
Control
The inside of an LLM is an incomprehensible spaghetti of transformers and weights. Once the model has been trained, control can only be exercised over its input or its output. In a knowledge graph, however, any concept can be removed or have access permissions applied to it. That concept (or its absence) can then be used to exercise control over the input or output of a language model.
Knowledge graphs also make it easier to formalise important "how to" or Procedural Knowledge. Prompts, personas, tone and style directives, policies, statutes... can all be defined like any other knowledge and applied at query time.
Efficiency
An LLM can take many seconds to respond. Completion is an expensive process - both in time and resources.
A typical knowledge graph application, however, will respond in milliseconds and it can be easily scaled to workloads of any size. A knowledge graph is designed to provide answers, so it can often provide them without using the LLM. When it does use the LLM, the context is much smaller than that typically provided by a chunked text database. This makes for faster, cheaper responses with a smaller carbon footprint.
Tuning
If your LLM-backed application is returning an answer you're not happy with, all that may be necessary is a change to a single fact or concept in your knowledge graph. Wrong answers can can be corrected, bias can be surgically removed.
Fine-tuning your application doesn't get any easier than that.
What does a KEG Stack look like?

There are many ways to implement Knowledge-Engineered Generation.
You can build your knowledge graph in RDF and use a custom model to create SPARQL when a query arrives. You can implement your knowledge graph in any of the dozens of property graph products or services. You can even utilise the Relationships in LlamaIndex to build a simple graph that may provide all the structure you need.
At FactNexus, we build and manage knowledge graphs using our GraphBase Graph DBMS. It's early days, but you can get a sense for the power of the KEG architecture at beth.ai.
At beth.ai you can see and play with simple KEG implementation using site plugins, Slack, Messenger or Telegram. You can even test drive a Graph Workspace that lets add concepts and facts and see the results. Let us know what you think.