
A Semantic Knowledge Graph is: a knowledge graph with structures and concepts that support semantic search of that graph.
We’ve been spoiled. Apple, Google, Amazon, Facebook... they all spend so much time and effort designing and tuning their products that, in most cases,we don’t even have to think about how to use them. In the bad old days, when we needed help using an application we were told to RTFM - Read The .... Manual. Now, if consumer software doesn’t "just work" in an intuitive way we’re inclined to throw it away and get some that does.
When it comes to our computer and phone applications we also expect them to give us immediate results. Instant gratification. And they usually deliver.
Semantic Search Makes Message-Based Q&A Possible
So it is with providing knowledge to our customers and our team members. They expect instant, easy-to-get answers and they expect to find them without reading a manual or learning a query language. That’s why there’s a move towards knowledge bases that can be queried from chatbots and from within messaging channels such as Facebook Messenger and Slack. These are familiar applications that people use every day.
If these message-based channels are going to provide answers, however, they need to be able to respond to natural language questions. They need to reference a knowledge base with "semantic" capabilities. Which is why enterprise is exploring semantic knowledge graphs.
But Isn't Every Knowledge Graph a Semantic Knowledge Graph?
There is a plenty of confusion about what constitutes a semantic knowledge graph. Semantic features are a key part of defining a knowledge graph – we even use it in our own definition: A knowledge graph includes semantic structures that allow both humans and machines to understand and reason about its contents. For this reason, many would argue that every knowledge graph is a semantic knowledge graph.
In that same article, however, I argue that Knowledge Graphs are for Humans. Sure, they’re also used by and managed by machines, but their uniqueness as a data structure comes from their power to capture understandings and package them for consumption by people.
Man's Google's Search for Meaning
Let’s assume for a moment that we have a knowledge graph and we, as humans, want to extract some knowledge from it. How do we achieve this?
If you do a quick search using Google, you’ll soon discover that there are many "query languages" designed to get information from a graph. SPARQL, Gremlin, Cypher, GQL, PGQL, GSQL, AQL, GraphQL, KGVQL...
The irony is that there is no GoogleQL needed for you to get answers from Google’s own knowledge graph. Google lets you use English. Or any of many other natural human languages. Try it for (say) "dog" and you’ll get a knowledge panel generated from the Google Knowledge Graph.
Google allows you to query their graph this way because it recognises that communication is a two-way street. The power to package up knowledge in human-understandable form is all very well, but it’s of no use if the human doesn’t know how to ask for it.
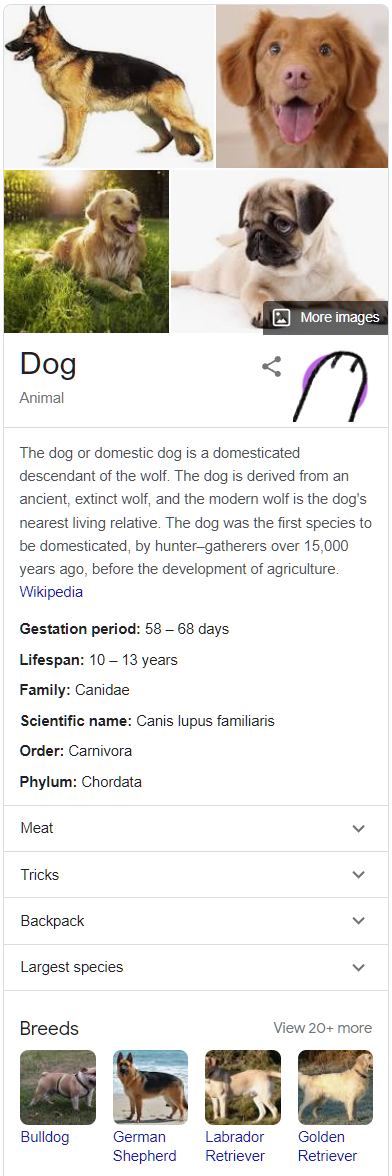
Revisiting our "dog" example. If you search for "canine" you’ll get the same knowledge panel. Try "chien" - you’ll also get the same panel - because chien is French for dog.
You get the same result because Google’s knowledge graph is not organised by word – it’s organised by meaning. Its structures are semantic. Its “dog” concept is a much more important part of its graph than the words that point to it. Google’s is a semantic knowledge graph because it takes the semantic content of your query (the meaning) and answers that from its graph (of meanings).
Semantics is the Study of Language
Google Assistant, Siri and Alexa all reference knowledge graphs and they let you use natural language to query them. They sit behind an intellectual property wall so it’s difficult to know exactly how they achieve this.
This much we do know. Neural networks and other forms of machine learning no doubt contribute to these knowledge graphs and the process of querying them – but certain natural language processing (NLP) steps are still required:
- Tokenization – breaking the query up into words.
- Part-of-speech tagging – are the words nouns, verbs, etc?
- Stemming and lemmatization – get the "base" of the word.
- Entity extraction – are the words a name for something?

The problem is that these processes aren’t enough, by themselves, to find the right meaning in a query and inform a reliable search.
Time flies like an arrow; fruit flies like a banana.
Natural language is too ambiguous, as anyone who's tried to implement knowledge search in a chatbot will tell you. What’s also needed is context - the context provided by the relationships a candidate concept has within a knowledge graph. A knowledge graph with the right knowledge knows that an arrow can fly ("flies"), but a banana cannot. This context allows the search to find the right concept in the knowledge graph.
Semantic knowledge graphs managed by Google, Apple, Amazon etc. will also carry ontological structures that further assist with the handling of natural language queries. These structures allow inference from properties (e.g. subsumption) that you can’t leverage with a simple index of words. Inference tells Google that a "dog" panel is the best result for a "canine" search if it can't return a "canine" panel.
A Definition
So there’s our definition: A Semantic Knowledge Graph is one with structures and concepts that support semantic search of that graph. One that supports search to match the meaning behind words.